Elasticsearch is a search server based on Lucene. It provides a distributed, multitenant-capable full-text search engine with a Restful web interface and schema-free JSON documents. Elasticsearch is developed in Java and is released as open source under the terms of the Apache License.
It provides scalable search, has near real-time search, and supports multitenancy. ElasticSearch is distributed, which means that indices can be divided into shards and each shard can have zero or more replicas. Each node hosts one or more shards, and acts as a coordinator to delegate operations to the correct shards. Rebalancing and routing are done automatically.
It uses Lucene and tries to make all features of it available through the JSON and Java API. It supports facetting, highlights, suggesters and percolating, Percolating which can be useful for notifying if new documents match for registered queries.
Another feature is called "gateway" and handles the long term persistence of the index, for example, an index can be recovered from the gateway in a case of a server crash. Elasticsearch supports real-time GET requests, which makes it suitable as a NoSQL solution, but it lacks distributed transactions.
ElasticSearch can scale out to hundreds of servers and petabytes of data.
 |
| Figure 1 |
Elasticsearch is much more than just Lucene and much more than “just” full text search. It is also:
A distributed real-time document store where every field is indexed and searchable. A distributed search engine with real-time analytics. Capable of scaling to hundreds of servers and petabytes(Figure -1) of structured and unstructured data .
ElasticSearch Requirements:-
Requirement for installing Elasticsearch is a recent version of Java. Preferably, you should install the latest version of the official Java from www.java.com.
You can download the latest version of Elasticsearch from elasticsearch.org/download.
curl -L -O http://download.elasticsearch.org/PATH/TO/VERSION.zip
unzip elasticsearch-$VERSION.zip
cd elasticsearch-$VERSION
unzip elasticsearch-$VERSION.zip
cd elasticsearch-$VERSION
Elasticsearch is now ready to run. You can start it up in the foreground with:
./bin/elasticsearch
Add
-d if you want to run it in the background as a daemon.
Test it out by opening another terminal window and running:
curl 'http://localhost:9200/?pretty'
You should see a response like this:
{ "status": 200, "name": "Shrunken Bones", "version": { "number": "1.4.0", "lucene_version": "4.10" }, "tagline": "You Know, for Search" }
This means that your Elasticsearch cluster is up and running, and we can start experimenting with it.
Clusters and nodes
A node is a running instance of Elasticsearch. A cluster is a group of nodes with the same
cluster.name that are working together to share data and to provide failover and scale, although a single node can form a cluster all by itself.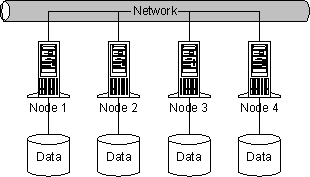
You should change the default
cluster.name to something appropriate to you, like your own name, to stop your nodes from trying to join another cluster on the same network with the same name!
You can do this by editing the
elasticsearch.yml file in the config/ directory, then restarting Elasticsearch. When Elasticsearch is running in the foreground, you can stop it by pressing Ctrl-C, otherwise you can shut it down with the api
curl -XPOST 'http://localhost:9200/_shutdown'
No comments:
Post a Comment