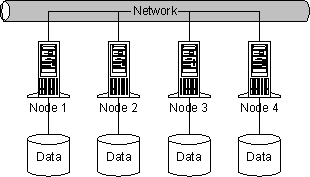
Sharding is a type of database partitioning that separates very large databases into smaller, faster, more easily managed parts called data shards and can be spread across multiple servers. The word shard means a small part of a whole.
The concept of Database Sharding has been gaining popularity over the past several years, due to the enormous growth in transaction volume and size of business application databases. This is particularly true for many successful online service providers, Software as a Service (SaaS) companies, and social networking Web sites.
The governing concept behind sharding is based on the idea that as the size of a database and the number of transactions per unit of time made on the database increase linearly, the response time for querying the database increases exponentially.
Additionally, the costs of creating and maintaining a very large database in one place can increase exponentially because the database will require high-end computers. In contrast, data shards can be distributed across a number of much less expensive commodity servers. Data shards have comparatively little restriction as far as hardware and software requirements are concerned.
Database Sharding Challenges:-

The reasons for the performance and scalability challenges are inherent to the fundamental design of the database management systems themselves. Databases rely heavily on the primary three components of any computer: CPU, memory and disk.
Each of these elements on a single server can only scale to a given point-after that, you need to take additional measures to improve performance. While it is common knowledge that disk I/O is the primary bottleneck, as database management systems have improved they also continue to take greater advantage of CPU and memory.
Therefore, as business applications gain sophistication and continue to grow in demand, architects, developers and database administrators have been presented with a constant challenge of maintaining database performance for mission-critical systems. This landscape drives the need for database sharding.
Historically, sharding a database required manually coding data distribution policies directly into your applications. Application developers would write code that stipulates directly where specific data should be placed and found. In essence developers were creating work-around code to solve a database scalability problem so their applications could handle more users, more transactions and more data.
In some cases, database sharding can be done fairly simply. One common example is splitting a customer database geographically. Customers located on the East Coast can be placed on one server, while customers on the West Coast can be placed on a second server. Assuming there are no customers with multiple locations, the split is easy to maintain and build rules around.
Using an example can help explain MySQL sharding more clearly, so let’s take the following table:

This is a small table containing a list of customers. Any modern database can handle such a table. But happens if instead the table has to store seven million rows instead of just seven rows?
Theoretically, this should not be a problem. But usually there are lots of operations on such a large table – for example we may have many read and write operations on this table every second.In practice, a very large customer table can become a database bottleneck. Why? Because it doesn’t fit in the database server cache anymore, because of database isolation management, and for other reasons that cause the database to crawl under load.
How does sharding solve MySQL Scalability?
If we take the customers table, and split it into four different databases, each database will contain 1.80 million rows. That’s still a lot, but less than 8 million rows. This will result in improved database performance. In fact the following diagram shows how such a table can be split:
MySQL Data Distribution Database
Every database will get some of the rows. In old-fashioned do-it-yourself sharding, it was the developer’s responsibility to create an efficient, application-specific data distribution policy that efficiently stipulated exactly where each row should be stored and found for each table. Nowadays, that work is simplified and automated using Mysql Clustering.
The concept of Database Sharding has been gaining popularity over the past several years, due to the enormous growth in transaction volume and size of business application databases. This is particularly true for many successful online service providers, Software as a Service (SaaS) companies, and social networking Web sites.
 |
| Database Size Grow Year By Year |
Additionally, the costs of creating and maintaining a very large database in one place can increase exponentially because the database will require high-end computers. In contrast, data shards can be distributed across a number of much less expensive commodity servers. Data shards have comparatively little restriction as far as hardware and software requirements are concerned.
Database Sharding Challenges:-
- Reliability
- Distributed queries
- Avoidance of cross-shard joins
- Auto-increment key management
- Support for multiple Shard Schemes
The basic concept of Database Sharding is very straightforward take a large database and divide into a number of smaller databases across servers. The concept is illustrated in the following diagram:
The reasons for the performance and scalability challenges are inherent to the fundamental design of the database management systems themselves. Databases rely heavily on the primary three components of any computer: CPU, memory and disk.
Each of these elements on a single server can only scale to a given point-after that, you need to take additional measures to improve performance. While it is common knowledge that disk I/O is the primary bottleneck, as database management systems have improved they also continue to take greater advantage of CPU and memory.
Therefore, as business applications gain sophistication and continue to grow in demand, architects, developers and database administrators have been presented with a constant challenge of maintaining database performance for mission-critical systems. This landscape drives the need for database sharding.
Historically, sharding a database required manually coding data distribution policies directly into your applications. Application developers would write code that stipulates directly where specific data should be placed and found. In essence developers were creating work-around code to solve a database scalability problem so their applications could handle more users, more transactions and more data.
In some cases, database sharding can be done fairly simply. One common example is splitting a customer database geographically. Customers located on the East Coast can be placed on one server, while customers on the West Coast can be placed on a second server. Assuming there are no customers with multiple locations, the split is easy to maintain and build rules around.
 |
| Fig 2. Separate Database table based on each location |
Using an example can help explain MySQL sharding more clearly, so let’s take the following table:
This is a small table containing a list of customers. Any modern database can handle such a table. But happens if instead the table has to store seven million rows instead of just seven rows?
Theoretically, this should not be a problem. But usually there are lots of operations on such a large table – for example we may have many read and write operations on this table every second.In practice, a very large customer table can become a database bottleneck. Why? Because it doesn’t fit in the database server cache anymore, because of database isolation management, and for other reasons that cause the database to crawl under load.
How does sharding solve MySQL Scalability?
If we take the customers table, and split it into four different databases, each database will contain 1.80 million rows. That’s still a lot, but less than 8 million rows. This will result in improved database performance. In fact the following diagram shows how such a table can be split:
MySQL Data Distribution Database
 |
| Data distribution Database |
Every database will get some of the rows. In old-fashioned do-it-yourself sharding, it was the developer’s responsibility to create an efficient, application-specific data distribution policy that efficiently stipulated exactly where each row should be stored and found for each table. Nowadays, that work is simplified and automated using Mysql Clustering.